How you can develop software in 2024
A while ago I made a post on reddit where I explained how powerful I feel when developing products with LLMs, and especially the most recent state-of-the-art model Claude Sonnet 3.5 from Anthropic. This post got a lot more traction than I expected, on both reddit and twitter. People have strong opinions, on one end of the spectrum we find people holding the view that with LLMs, even non-technical people can develop technical products. On the other end of the spectrum we find people that hold the view that LLMs are useless.
In my view, the truth is of course somewhere in between. As I hope this article will show you, LLMs can be very useful when developing software, but we will also see situations where a non-technical person using an LLM would get into serious trouble.

So, when are LLMs good?
I think LLMs currently shine on tasks that are not fundamentally difficult, but that still takes time to implement. We can call these “easy but time-consuming tasks”. This might sound limited (and in a sense it is), but a large part of all applications fits into this criteria. Lets take a look at an application like Instagram. What parts are obviously hard?
- Their machine learning
- Their backend systems that are necessary because of their scale
For example recommender systems and content moderation.
Here I'm hinting at the things you need to do when your application has 100m+ DAUs, but don't need to otherwise.
What parts of instagram are not fundamentally difficult, but still takes time to implement? Almost everything else (if I have forgotten something incredibly difficult, chances are that if you squint your eyes, you can put it in the second bucket). For example:
- UI development (translating design mockups into actual code)
- API integrations
- CRUD operations
- State management
I'm not saying that these things are dead simple, but I think it's fair to say that there is a difference in complexity between working on the recommender or database infrastructure and working on turning design mockups into react.
Putting LLM-driven development to the test
Lets see how far we can get with an LLM by developing an application that while not being fundamentally difficult, isn't completely trivial either. I might as well kill two birds with one stone here and develop something that I've wanted for a while, but hasn't had the time to develop.
I've always been a fan of flashcards (I've used Anki) but I've never really had any consistency in using them because of the simple fact that I don't enjoy the process of creating them. On the other hand, I have no problem with reviewing already created cards. Because of this, I'm thinking that we should automate the creation of cards. The flashcard generation process will look something like this:
- You upload text of what you've just read (e.g chapter 1 of a book)
- A LLM creates flashcards based on the text and adds them to your deck.
Many people claim that the actual creation of cards are essential for learning, but we should still get some benefit from reviewing cards even if we didn't create them. The alternative for me is that I don't review what I've learnt at all, because I can't be bothered creating the cards. To balance out what we lose by not creating the cards ourselves, we will add a “deep dive” feature that will work like the following:
- Every flashcard will have an associated conversation. Example usage would be that you answer a card incorrectly, and you then dive into a conversation with a model about the card. Hopefully, what you learn in that deep dive will help you the next time you try to recall the card.
- The ability to add, edit and delete flashcards
- The ability to add, edit and delete decks
- The ability to review flashcards according to a scientifically backed scheduling algorithm
- The ability to generate flashcards automatically from a chat
- The ability to discuss an existing flashcard in a chat
- We create the normal flashcard app
- We add the LLM functionality
Not demoware
- the codebase should be maintainable and of high quality
- the product as shown in videos should behave the same for everyone that tries it
How we will develop Deepcards
I normally use a combination of “handwritten code” and “LLM generated code”. However, for this project we will not use any handwritten code at all. This means that even if I know how to change something, I will try to prompt the LLM to change it instead.
To make this easy to follow on this blog, I developed a feature for viewing the LLM conversation to the right next to my writing. When you reach certain positions or click on highlighted text to the left, the LLM window will automatically focus on relevant sections. I couldn't figure out how to represent the LLM window in a nice way on small screens, so if you are on mobile you will only see my writing.
I've mostly referred to the model we will use as “the LLM” so far, but lets get more specific here. We will use Claude Sonnet 3.5 from Anthropic. It's top 2 on most LLM leaderboards together with GPT-4o from OpenAI, but if you ask people that use LLMs daily for coding I think it's very fair to say that most will tell you that Claude Sonnet 3.5 is the clear cut number one. That is also my personal view after experimenting with all of them, so for this blog post we will use Claude Sonnet 3.5 and I will from here on out refer to it as just Claude.
For interfacing with Claude I will use the web app at claude.ai, and this might confuse some people that are used to LLM interfaces that are integrated into their IDE like Cursor, Codeium and Copilot. I like these product when “handwriting” code for their autocomplete, but I don't think any of them has nailed the other features yet. It would also be more difficult to represent the workflow in text if I were to use any of these products, so for this project lets keep ourselves to the Claude web app.
Things to keep in mind
- Serious trouble for a non-technical person:A hot debate right now is, how useful are LLMs to non-technical persons for coding? I think we will get to several situations in the development of this product where a non-technical person would be in serious trouble, so lets keep a counter for the number of times that happens.
- Local 10x improvement:Some people often talk about LLMs 10x:ing their productivity, and while I think this in aggregate is not possible currently for a good developer, I do think there are situations where we can get local 10x improvements with LLMs.
- Counterproductive usage:Sometimes you get to a point when relying on LLMs where you think to yourself, damn, I probably should have just programmed this by myself from the start instead. This is when using the LLM is in a sense counterproductive.
Structure for the rest of the article
There are going to be two sections now where you can follow the development of Deepcards in detail. In the first section, we will create a fully functioning flashcard app. That will be followed by some thoughts about how it went accompanied with some ideas of how we can change our workflow for the second section, which will be about adding the LLM functionality.
Notes from the future
We have in total 31 different conversations, 11 in the first section and 20 in the second section. The first section is more focused on what Claude is doing, and is generally less interesting from a technical perspective. The second section is more focused on the features we are developing, and I'd say is more interesting from a technical perspective. You might not have the time to read all the conversations, so I left a few comments below in the table of contents under the sessions that are more interesting . Anyhow, here is the table of contents so you can jump around:
Remaining Table of Contents
- Section 1: Development
- 1.1 Introduction to the blog LLM tool
- 1.2 Planning
- 1.3 Getting started
- 1.4 Setting up the server
- 1.5 Review functionality
- 1.6 Creating cards
- 1.7 Adding sidebar
- 1.8 UI improvements
- 1.9 Creating a home page
- 1.10 Adding more advanced functionality
- 1.11 UI improvements II
- 1.12 Code review
First conversation where we increment every value in the counter. In other words there was serious trouble for a non-technical person, a local 10x improvement and also some counterproductive usage.
The first of 6 (!) UI improvement sessions.
First session where I feel that I maybe didn't get an aggregate productivity improvement.
First of several code review sessions.
- Thoughts after section 1
- Section 2: Development
- 2.1 UI improvements III
- 2.2 Chat UI
- 2.3 LLM integration
- 2.4 UI for LLM generated flashcards
- 2.5 Changing the layout
- 2.6 Chat persistance
- 2.7 Generating flashcards
- 2.8 Code review II
- 2.9 Making it good
- 2.10 Security review & improving auth
- 2.11 UI improvements IV
- 2.12 Profile settings
- 2.13 Spaced repetition algorithm
- 2.14 UI improvements V
- 2.15 Optimizations and scalability
- 2.16 Deployment
- 2.17 Mobile UI issues
- 2.18 Prompt engineering
- 2.19 UI Improvements VI
- 2.20 Code Review III
We add actual functionality to the chat UI.
We finally make it possible to get flashcards from a chat.
We add code and math rendering, and and also automatic naming of chats
Huge session where we do a big design overhaul. We also make the UI work on mobile.
A deep dive into the spaced repetition algorithm we use on the site.
We finally deployed the application.
We improve the prompt we use for flashcard generation.
- Final product and thoughts
Introduction to the blog LLM tool
As you can see to the right, we have a dropdown for the different chats. We have a dummy conversation loaded right now, and if you click here you will get to it's first message. If you click here you will get to it's sixth message, which is the first one including a code snippet. You can collapse individual code snippets, but you can also change from "showing code by default" to "hiding code by default" if you feel like the code takes up to much space. This will probably be useful in later chats when there are going to be large code snippets that are just being referenced back and forth, especially if you are more interested in the conversation than the code-specifics.
Now you know how this tool works, and we can move on to development!
Planning
Lets start by telling Claude about our idea and see if it has tips for features to add. Most (if not all) of the tips we get back are obvious, and not necessary to define this early. We move onto figuring out our tech stack.As you can see I have some preferences and we take that into consideration. We have a somewhat interesting discussion over the backend, and we arrive to the conclusion to use supabase auth and supabase db (which is postgres), but to still have a server layer in between that we control. Here's the summary of the conversation
Getting started
At this point we have made some tech stack decisions and we have also decided what our application architecture will look like from a basic point of view. We are now ready to set up the project, which we do by following the commands outlined by Claude. When the frontend application is up and running, we decide to implement some basic UI components. As you can see I'm not impressed by the design initially, so we iterate on that until we get to something better.
We then move over to authentication. We have already decided to not roll our own auth and to use supabase, so I just follow all the instructions outlined by Claude for setting up supabase. Since we want google sign-in, we also need to configure some stuff in the google cloud console. At this point, there have been zero issues. We have a some type errors that Claude fixes for us. We now have google authentication working for our product.
Counter
The supabase setup and integration into our frontend was super quick, probably took something around 10 minutes. I'm not that familiar with supabase, so I think it's fair to say that I would have to spend at least 1 hour by myself here otherwise (reading the docs and implementation). Every step outlined by Claude was correct here, and I just had to follow step by step. I think it's fair to say that we have our first local 10x improvement!
- Serious trouble for a non-technical person:0
- Local 10x improvement:1
- Counterproductive usage:0
State of the project
Setting up the server
Here we move on to setting up the server. I give some instructions for how we should set up or first endpoint and then we create our first table in the database, and we write our authentication middleware that integrates with the supabase client. We set up our authenticated routes and test them by locally by grabbing a JWT from the chrome console, and sends request with the vscode rest client.
After verifying that our endpoints work as expected, we move back to the frontend. Claude moves to the code way to fast here, and I tell it to chill, we first need to think about our code before writing it. I propose that we use react-query for server state because I'm familiar with it, and then we create the initial page for reviewing your cards. Always having the quality of our codebase in mind, I propose to Claude that we should create custom hooks with react-query. Here all of a sudden after pasting I see that we are getting errors! It appears that Claude is using an old version of react-query, and I also note that we should always use the library defaults until we notice a problem.
When starting to fetch from our actual server, we get the famous CORS error, which Claude fixes without issues.
Counter
While Claude nailed how to get the client and server set up with step-by-step instructions, I think setting up the authentication on the server and trying it out by grabbing the JWT from the console would have been to much for a non-technical person. I'm also having trouble seeing them work out how to use react-query here, especially when Claude gives us syntax from an earlier version. Therefore, lets bump up that score to 2.
- Serious trouble for a non-technical person:2
- Local 10x improvement:1
- Counterproductive usage:0
State of the project
Review functionality
Moving on to setting up the review functionality. One thing that you can see that I like to have in context in every conversation is the current database schema and the file structure. As I tell Claude here, I like to practice UI driven development where I first imagine (and maybe sketch out) what something should look like, implement it with dummy data, and only after that integrate real functionality.
I know that there is some science behind space repetition algorithms, so I ask Claude about it. I get a good answer, and we decide to use the SuperMemo SM-2 algorithm. I ask Claude for step by step instructions, and I get them. They are mostly good, but Claude doesn't follow the pattern when using react-query as we have used previously. Using different patterns like this is obviously bad, and I remind Claude and they come back with better code.
After a while we have the review functionality up and running, but there is some janky behaviour in the UI. I suggest to Claude that we should use optimistic updates here to fix it, and Claude agrees. We get some more issues with the card rendering, and Claude suggests a solution with useEffect that I don't like. After trying a few things, I get enough and take a step back and actually start using my brain. After outlining the problem, Claude finally realizes how to do it (using a key prop on the flashcard component).
We then fix some bugs in the UI and add react-router for routing functionality. I get mad at Claude for changing the UI when that had nothing do with what I ask for. This sometimes happens, and is pretty annoying.
Counter
We had another 10x local improvement when implementing the spaced repetition algorithm here. This took maybe 2-3 minutes and worked immediately, safe to say that this was a 10x improvement. On a negative note, I think we had our first instance of counterproductive usage here when we got the UI jank. I think I would have been able to solve this faster by myself. This would also result in serious trouble for a non-technical person, and when Claude used a bad pattern for react query likewise.
- Serious trouble for a non-technical person:4
- Local 10x improvement:2
- Counterproductive usage:1
State of the project
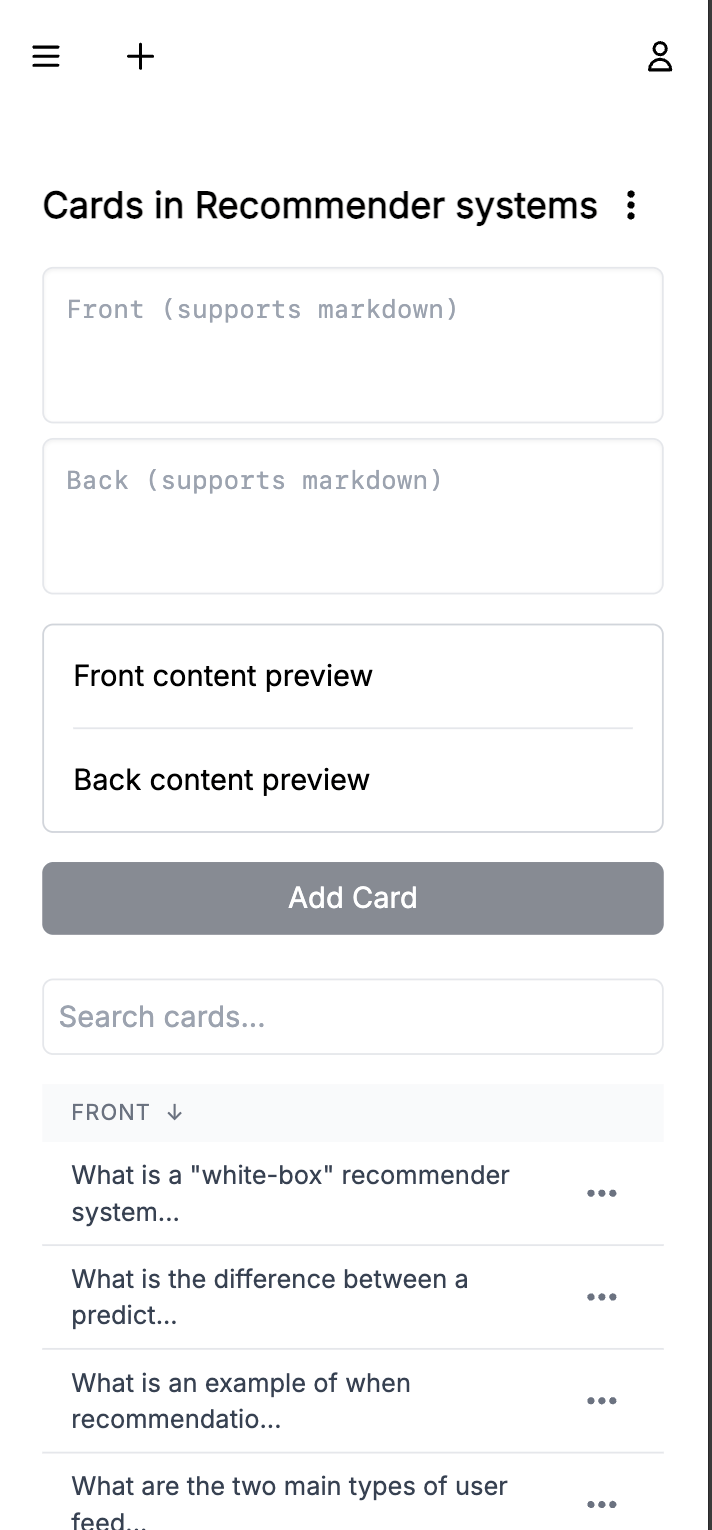
Creating cards
We now move onto thinking about the functionality of creating cards. As usual I summarize what we have done so far along with the DB schema and project file structure. What's new here is that I provide a mockup (that I just created in excalidraw) which provides the structure of the page I'm imaging. We iterate on the UI here, and I think this workflow is kind of nice where I give Claude a list of changes I want to see and just get them. Feels like programming in english!
We change our schema to fit the UI, and start working on new routes on the backend. Claude gives me an ugly sql query that we fix. After all the new routes are confirmed to be working, we move back to the frontend where Claude once again uses the wrong react-query syntax.
We move on thinking about how we should display already created cards, and I suggest tanstack table which we decide to use. It basically works on the first try, and we move on to the delete card functionality. Claude messes up a react-query hook, and I point out the issue and we fix it. Finally, we add the functionality of creating a new deck, where we have some issues with whether we should generate UUIDs on the client or the server.
Counter
Serious trouble when Claude gave us a bad react-query hook, and when we got the issue with UUIDs. Local 10x improvement when we added tanstack table in like 2 minutes.
- Serious trouble for a non-technical person:6
- Local 10x improvement:3
- Counterproductive usage:1
State of the project
Here you can see the UI for creating cards, with all the functionality working.
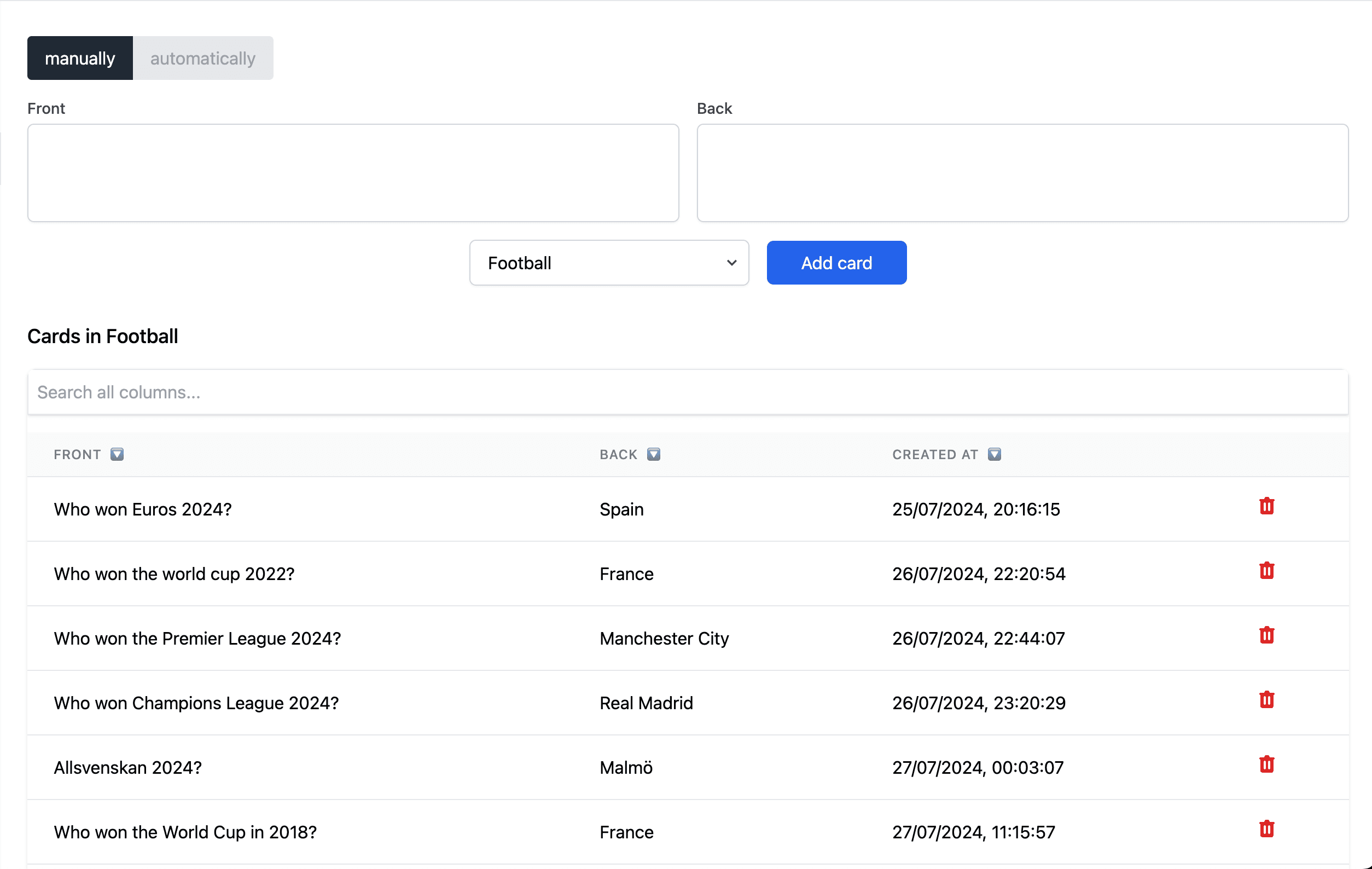
UI improvements
Now we start a session where we just want some UI improvements. These sessions are generally very good. In the end it's not only UI improvements as I decide to add a dashboard page as well.
- Improving the UI for the review screen
- Issues with positioning
- Improving the Flashcard component by adding space bar navigation
- Create dashboard page
- Adding real data by providing step-by-step instructions
- Claude forgets the authentication middleware
- Issue with SQL query
Counter
Serious trouble when Claude didn't add the authentication middleware, and when there was an issue with sql query.
- Serious trouble for a non-technical person:8
- Local 10x improvement:3
- Counterproductive usage:1
State of the project
The review screen we just added:
Creating a home page
At this point we want a home page, what users that aren't signed in will see. Here I trust Claude to give a good design without even providing a mockup, and they do a good job!
- We add a login modal (suggested by Claude)
- Pretty cool how we can just add the Google SVG because Claude has it memorized
Counter
Creating the homepage was definitely a 10x local improvement, we didn't even have to think about the design. Adding the modal with it's functionality aswell.
- Serious trouble for a non-technical person:8
- Local 10x improvement:5
- Counterproductive usage:1
Adding more advanced functionality
Here I have this idea that I want the sidebar to show how many cards are due, and that it should be possible to review cards on a per deck basis. We iterate on the design here for a while, and there are some bugs that we squash.
- Claude gives us a bad SQL query
- Claude tries to access a field on a variable that doesn't exist, I have to come up with the solution
- Claude comes up with another bad SQL query
- I have to remind Claude that we sometimes should invalidate react-query queries
- I notice that we have snake_case in the javascript at some places, Claude fixes it
- I get an idea for improving the UI, which is to move the decks to the sidebar under "Cards".
- Claude makes a mistake with protected routes
- Claude adds a line for our react-query query that makes it not work
Counter
This was the first part of the project where I felt like Claude was a little annoying. Apart from the UI parts of the sidebar and the quick change of how we changed the viewing of the decks (which were 2 other local 10x's), I think I would have been able to do the rest faster without Claude, so this gets in the bucket of counterproductive usage. Also, from the bulletpoints above we can see that there were atleast 6 places where a non-technical person would get serious problems.
- Serious trouble for a non-technical person:14
- Local 10x improvement:7
- Counterproductive usage:2
State of the project
All in all, I think it's starting too look pretty good:
UI improvements II
Here we have three goals in mind, we want add the possibility to remove decks, we want to render cards in markdown and we want to make the loading state UI prettier.
- Adding a settings modal with delete and rename functionality
- I notice that we have two modals when we only need one
- We start working on better loading states
- Common theme, removing unnecessary useEffects that Claude adds
- Adding markdown support for rendering cards
Counter
I think the settings modal was another local 10x, not mainly because of the implementation but because of how Claude came up with it. Serious trouble once because of the unnecessary useEffects and one extra uncessary modal (stuff like this would lead to very unmaintainable code).
- Serious trouble for a non-technical person:15
- Local 10x improvement:8
- Counterproductive usage:2
Code review
This is a very important section. After copy pasting so much code, you get to a point where you don't have a good overview of the codebase. I felt that I needed to take the time to just read the whole codebase, ask clarifying questions and remove code that wasn't necessary. This also led to some improvements. Notable things:
- I try to be clever and remove some things and Claude agrees.
- Refactoring messy react-query hooks into multiple hooks
- Claude adds an unnecessary useEffect (again)
- We look at the sidebar
- Removing loading states where we use optimistic updates
Turns out I was wrong after thinking a bit, so this is an example of Claude not really having strong opinions and just agreeing
Claude suggests that we use a modal for creating decks and I agree
A common theme through the whole conversation, we have code where we update the UI optimistically but where we are also waiting for confirmation from the server
Counter
Here there were just so many things that I used my technical intuition for, so it's in my opinion fair to say that a non-technical person wouldn't be able to do this section. Let's not go over board, so we bump up the score twice. While it was nice having Claude as an assistant here, I don't think it was a 10x improvement.
- Serious trouble for a non-technical person:17
- Local 10x improvement:9
- Counterproductive usage:2
Thoughts after section I
I think it's fair to say that we now have a functioning flash card app. I can create decks, add cards and review them according to a scientifically backed scheduling algorithm.
State of the project
Here's what it looks like after the first section:
Review
Lets look at the counter, along with some thoughts.
- Serious trouble for a non-technical person:18
- Local 10x improvement:7
- Counterproductive usage:2
I think it's fair to say that while Claude is very impressive, the claims that non-technical people are now able to create fully functioning software products with it are not really grounded in reality.
These are interesting, but worth noting that they are often for easier, boilerplate tasks. Like, it's not most often the 10 day task that takes 1 day, or even the 10 hour tasks that take 1 hour. It's more like the 30 minutes task that instead takes 3 minutes. While this is nice, it's obviously not close enough if we want to claim a total 10x increase in productivity.
This happened when I didn't have a great grasp of the codebase and just copy pasted like a maniac. This is why code reviews are so important. When you don't fully grasp what your code is doing, and keep copy pasting in new stuff it quickly spirals into something that leads to errors. You can't offload understanding of your system to the LLM!
- A non-technical person would get into too much trouble
- We get a bunch of local 10x improvements for small tasks
- Using Claude can be counterproductive when I'm sloppy and not focused
While using Claude so far hasn't led to a 10x increase in my productivity, I believe it did enhance my efficiency to some extent. However, the most significant improvement isn't necessarily the speed at which I can complete tasks; rather, it's the reduction in mental effort required. I just feel like programming by expressing ideas in english demands less cognitive effort than doing traditional programming.
To put it into perspective, I have been working on this project primarily during evenings and weekends for the past few days. Had it required the same level of cognitive effort as "normal programming," I might not have been as motivated to dedicate that time. One could argue that I would have been capable of creating this project in a comparable timeframe without the assistance of Claude. However, the actual hours I would have needed to invest would have demanded more intense focus. In contrast, these sessions, where I'm programming by articulating my thoughts in english, are much more chill.
As specified earlier, we let Claude write all the code here. If I were to do a mix of letting Claude write code, and write other parts of the code myself, I think this would have gone even faster. But for this blog post, we will keep letting Claude write ALL the code!
Section II
- Deep dive feature
- Chat
- Automatically generate flashcards from chat
UI improvements III
As mentioned above, we will now try to write better prompts. I start by summarizing the application as usual, and I then go into detail of how I think we can improve the UI on the cards page along with a mockup from excalidraw. After iterating a bit on the design, we get to a good solution very quick, and we test it with some "semi-advanced" markdown.
Before:
After:

I think this looks pretty good! We also add the possibility to edit already created cards. This is an example of something that went perfect, I gave Claude all necessary context and we got a result that worked on the first try.
- We look for improvements in the review UI
- We once again remove a useEffect
State of the project
Chat UI
We finally get to a more exciting part where we add the "deep dive feature". I provide a somewhat detailed description of what I'm imagining, along with two excalidraw mockups. We use our favorite prompt, just giving Claude a list of UI improvements. We do it again. And again.
- I point out a logic error that we fix
- I notice that we don't encapsulate functionality like we should
While fixing this, Claude messes up some styling that previously worked fine (a somewhat common theme)
State of the project

LLM integration
In the previous section we implemented the chat UI with dummy responses, now lets do the actual LLM integration! As you can see, my initial idea was to let users provide their own api key and interact with OpenAI directly from the client. However, after reading that OpenAI isn't really a fan of this pattern, we decide to let everything go through our server. Instead of allowing the user to provide their own key, I'll just utilize the fact that I have $500 in OpenAI credits and let everything go through my key.
- Step-by-step instructions for the OpenAI integration
- Bugs that we squash one by one
We go back and forth for a bit until everything works.
State of the project
UI for LLM generated flashcards
We now want to look into the possibility of generating flashcards automatically from conversations. The idea here is that you should be able to have a conversation, and then ask for some flashcards that will help you remember what you learnt in the future. We explore this as a concept before diving into the code. After figuring out what the user experience should be like, we start implementing the UI with dummy data. After iterating on the design for a while (in our usual fashion by just providing bulletpoints of improvements), we get to a design that we are happy with:
We then move on to slowly integrating real functionality.
- We get some issues with a library we add "headlessui"
- We add a general "chat" choice in the sidebar
- Claude messes up the old styling when making an unrelated change
- We squash a few bugs one by one
Changing the layout
Here I get the idea that I want to change the layout a bit. Read it if you want, but it's not really that interesting.
- Making the sidebar dismissable
- Changing the font
- Adding a settings dropdown instead of logout button
Chat persistance
Currently the chats we have are just stored in memory, and are not persisted anywhere. We now want to add persistance! Here we start from the schema, and work our way up to to the UI. This all just a bunch of CRUD stuff, we basically just add routes, create react-query hooks and incorporate them into the UI.
- I remind Claude that we should utilize the powers of react-query
- Discussion about generating uuids on the client or the server
- Discussion about schema changes for automatic card generation
State of the project
Obviously we haven't implemented the actual flashcard generation yet, so that's why you see react cards in a discussion about carbon capture.
Generating flashcards
Now we finally get to the interesting part of the application!
- We think about the feature
- We use Zod and Instructor for getting structured output from the LLM
- I get a little mad because we are on the verge of counterproductive usage
- Claude gives me a crappy sql query
State of the project
Generating flashcards from a chat:
Code Review II
This was supposed to just be a code review session, but it ended up being much more.
- Adding flashcards as part of conversations
- Improve how we generate messages
- Improve flashcard generation
- Start persisting rejected flashcards
- Realize that we can use types generated by supabase
- Realize that it's better UX to generate flashcards inline than in a modal
This goes on for a while and it's not that interesting
If you are interested in the generative AI part of the application, most of the interesting stuff will start somewhere around here.
Obviously it's useful for the LLM when generating new cards to have accepted AND rejected earlier cards in the prompt
Big mistake that we didn't do this earlier. Sometimes it's still good to read the docs! Kind of funny that I counted adding supabase as a 10x improvement in the beginnning because I did not have to read the docs, and now we probably lost more time here than we gained there. Anyway, we replace all manually created types on both the server and client, and this becomes a pretty annoying side task but leads to a better looking codebase in the end.
This results in a big UX improvement in my opinion (I dislike modals generally). Before and after below.

Making it good
This was also a code review session, sort of. This is where I think the app actually becomes good.
- We add some basic error handling
- Claude gives me an overengineered abstraction
- Rendering code and math
- Automatic naming of chats
This happens once in a while. You really need to push for simplicity over complexity.
We add react-syntax-highlighter and katex, and have to work through a few bugs until we get it to work. Rendering math is a little harder than expected because we just get back text from the LLM. Claude provides a "classical" solution, that made sense in the age before LLMs. However, now that we have LLMs that are so good at following instructions, we can just ask the LLM to gives us math in the format that katex can render directly by improving the prompt. This looks pretty good:

Easily achievable with instructor!
State of the project
I'd go so far to say that this an actual useful product right now:
Security review & improving auth
I start with the goal of adding password based authentication, but instead we end up doing a
- security review of the application
- Implementing password based authentication
We discuss row-level security (RLS) and we agree that it's not necessary for our current setup.
After some thinking I decide to do magic links and OTPs instead of passwords. We go back and forth a bit for designing the signup/signin UI.
State of the project
UI improvements IV
This was a really cool session where we just go through the app page by page and make the design actually good. We tell Claude in the beginnning that we want a "linear-inspired" design, and this is basically the design you see on most modern SAAS products, inspired by linear.app. Instead of going through the conversation here by text, I'll just provide you with some before and after images. I think the general look and feel with font sizes and spacing across the application is the biggest improvement!
Before


After
At this point, none of our views are mobile friendly so this becomes our next job. Here are some of the mobile views:


Profile settings
Here I felt that it was time to create something that allowed users to change their settings. Like, default language model, spaced repetition algorithm and light/dark mode.
- Discussion about how to store user settings
- Set up trigger for creating profile on user creation
- UI/UX for changing settings
We decide to use JSONB on the profiles table instead of individual fields
Spaced repetition algorithm
This was an important session as I hadn't really dived into exactly our spaced repetition algorithm worked earlier.
- Start thinking about a design where users can choose basic or advanced
- Start looking at a modified SM-2 algorithm (like Anki)
- Our decided review function
Claude starts throwing code at me directly, even though we are just in the thinking stage (I hate that). We find some unused stuff in our schema that we remove. Time zone discussion.
Most interesting part here is that we like Anki now label cards as either being in a learning stage or review stage, with the review schedules being different. Claude continues to throw code at me when I don't want it.
We want the users to be able to choose "advanced" or "basic" spaced repetition algorithm, and we come up with a clever solution that avoids complexity.
State of the project
UI Improvement V
Okay you are probably sick of these UI Improvement sections so I won't write much here. Most important UI changes here is that we make it possible to modify suggestions and cards wherever they appear.
- Realize that modified suggestions are important for the prompt
While chasing UI bugs we realize something more important, that we need to change our schema bit to allow for modified suggestions, and that we need to save the original suggestions because that's valuable info for the LLM.
State of the project
Optimizations and Scalability
I thought this was going to a be an important session, but there wasn't that much to optimize. We analyze a few queries, but realize that they are all fast enough. We start discussing rate limiting, and Claude almost convinces me of using redis, but after some back and forth and realizing I have 0 daily active user (to be fair, 1 with me) I decide to put Redis in the bucket of overengineering for now, and just go with an in-memory rate-limiting solution (yes redis is also in-memory but you know what I mean).
Deployment
Finally, we get to an interesting session.
- Choosing our stack
- Cloudflare sucks
- Drinking the Google Kool-Aid
- Deploying the server on Cloud Run
- Deploying the frontend on Firebase Hosting
I like Cloud Run on GCP since earlier, so I'm pretty set on using that for the server. After some discussion I get interested in Cloudflare Pages for our frontend, mainly because of all the good things I've heard about Cloudflare. I almost get tricked into using Cloudflare for the server aswell, but decide that Cloud run is better in the end. I then buy a domain on namecheap, and start signing up at Cloudflare.
I immediately notice that the Cloudflare dashboard is very buggy and bad, but I'm like whatever, I've only heard good things about Cloudflare. What happens then is that I try to sign up for a paid plan. I give them my card info and click the button, and wait. It's taking a long time. After 2-3 minutes I get to an error screen. Okay so what I assume happened now is that I either got charged AND got upgraded to the paid plan, or that I didn't get charged AND also didn't get upgraded to the paid plan. But no, what happened is that I got charged and did NOT get upgraded to the paid plan. This is just embarrassing by Cloudflare on so many levels, so I realize there is no way I'm going to use Cloudflare for anything. (I opened a support ticked immediately, I have not gotten a response yet in 5 days, and I'm still on the free plan even though I payed $240). A complete joke, and by looking at their forums I see that this is a common problem.
We swap out Cloudflare Pages for Firebase Hosting, which is nice because now we will have both our server and frontend on GCP.
We struggle a bit with docker of course but after a while we are up and running.
Mobile UI issues
When deploying, I for the first time tested the UI from my actual phone, and there where some issues that didn't show up in the chrome console mobile view.
- Input zoom bug
- The 100vh problem
- Remove stupid manual header height calculation
Prompt engineering
This is an important session, where the focus is to improve the prompt given to the LLM for generating flashcards.
- What is a good flashcard?
- Improving the prompt
- Improving the math rendering instruction
- Continue to struggle with math rendering
We include the characteristics of a good flashcard in the prompt, along with a few good and bad examples.
We have some issues here, which requires some debugging. We finally fix it, and the bug was that the LLM gave us text with latex text mode inside of latex math mode, which apparently Katex doesn't like.
Everytime I think it's fixed, I notice another problem. This leads into a very annoying bug hunt that lasts for a while. Read if you want to. String processing is hard.
UI Improvements VI
Another UI improvements session? Yes. Why do we have so many of these? Because I use the app and notice things I'm either annoyed of or want added. The only interesting part here is probably when we design the homepage. Also, I ask Claude why they give me complex solutions when simple and better ones exist.
State of the project
The homepage:
Code Review III
The final code review before releasing this blog post, so I mainly just want to make sure that there isn't any stupid stuff left in the codebase.
- Modifying the client folder structure a bit
- Quick bug fix
The final product
Finally, we are finished. Below you can see a video where I:
- Log into my account
- Create my first deck
- Add some cards manually
- Start a chat about abstract algebra
- Generate a few flashcards from the chat
- Review the flashcards
- Go into deep dive mode for one of the flashcards
You can view the source code at github.com/holma91/deepcards, and try it out yourself at deepcards.ai It's completely free as I'm subsidizing the LLM integration with some OpenAI credits I have since earlier.
Evaluation
Since we are now finished developing this product, we can finally move into evaluation. I have so many thoughts after this, and I will try to structure it in a good way below.
The Good Stuff
UI development
- Coming up with the design
- Implementing the design
- Adding interactivity
I can't speak that confidently on how much of this is improved by Claude since I'm not a designer, but I can say that I think our app looks pretty good if you have in mind that no designer at all was involved in it's creation, and I can definitely say that it looks better than what I would have been able to come up with by myself.
I think this is a literal 10x improvement. Before LLMs, I dreaded this part because it's the greatest example of “time-consuming but not difficult”. You'd have to read CSS or tailwind docs in detail, and then carefully implement your designs. I don't think anyone enjoys this, and everyone probably agrees that in an ideal world this step doesn't even exist, the design in Figma or whatever should just automatically work in your app. It feels like we are almost there now with LLMs. I don't think I had to even once consult the tailwind docs for this project, but we still have an app that adheres to good design practices and works like a charm on both desktop and mobile.
At this point you have the component, but it doesn't do anything. This is where you add state management, event handlers, integrate with the data fetching logic, connect the component to the rest of the application's logic etc. Claude is pretty good here, but it's really important that we provide all the necessary context. For example, in my app we use react-query for basically all data fetching. If I want Claude to do this step well, it's very important that I mention that they should use react-query and provide examples of how we use it already in the application. Otherwise, I found that Claude by default just adds a bunch of useState and useEffect, and if you know React you know what a mess of a codebase that can lead to. While I think this step is definitely improved with Claude, I do think it can be annoying to always have to provide this context. I guess this is where integrated LLM experiences like Cursor and Copilot theoretically should thrive.
- use black for all buttons, not blue
- the flashcard should be shown on the top of the chat, in the same style it is shown when not chatting
- use best practices for setting the width of the chat, think about how chatgpt does it for example
- figure out some way to show which message belong to who (but don't use any crazy colors, we are minimalistic)
- put the close chat button to the top left or something, and make it small
- send button (if we even need a button that literally says send, could you an arrow up icon like ChatGPT) should be on the same line as the message box to the right, or included in the box somehow.
Claude is very good at this, and this way of improving the UI is a huge improvement for me compared to earlier. There is something about not having to consult your brain for detailed CSS knowledge for every minor tweak that significantly reduces cognitive load. This allows us to focus on the higher-level design decisions and user experience improvements, rather than getting bogged down in the implementation (CSS specifics in this case).
As an assistant for system design
The improvements here are not in the same level as UI development, but I still think Claude has been helpful when discussing tech stacks, database schema, how we should deploy the application etc. I must admit though that in all these discussions, I already had a pretty good view of the subject at hand before starting the discussions. It's still helpful though especially if I'm unsure of something and want discuss the pro's and con's of different approaches.
The Less Good Stuff
Context and communication issues
- How do we manage state?
- How do we fetch data?
When we have these patterns, it's essential that we use them everywhere, because the codebase will be a complete mess if we manage state differently in different components for no reason whatsoever. Lets say we have a page for cards that uses react-query for fetching them and handling their state. Then we want to create another page for decks, but we don't tell Claude exactly how we did it for cards, then you will most often get a response that uses useEffect and useState instead. At this point you'll have one pattern for fetching and state management on your cards page and another one on your decks page, for no reason. Both might work from a user perspective, but this inconsistency in code patterns will quickly lead to a difficult-to-maintain and frankly disgusting codebase.
Because of this, we consistently need to remind Claude about the established patterns in our codebase, either by pasting code examples or explaining. This creates a cognitive overhead. You're not just thinking about the new feature you're implementing; you're constantly cross-referencing with existing code to ensure consistency. This constant syncing between your understanding of the project's structure and Claude's understanding can be exhausting, especially as the project grows larger and becomes more complex.
While tools like Cursor and Copilot aim to address this by providing context automatically, the reality is that managing this context remains a significant part of the developer's role when working with LLMs. Basically for a feature you get to the following equation:
Time(explaining the problem to the LLM) + Time(giving the LLM enough context) + Time(getting a correct implementation from the LLM) < Time(implementing it correctly by yourself)
Time(explaining the problem to the LLM) + Time(giving the LLM enough context) + Time(getting a correct implementation from the LLM) ≥ Time(implementing it correctly by yourself)
For small features that require large context to do correctly, I still often think that I can implement it faster by myself. I think this basic equation explains fairly well why some experienced programmers in large companies still don't use LLMs, because the context required for a small change is often huge. At that point it's just not worth it to try syncing the LLM with your brain.
Code generation quirks
- Moves to code too quickly
- Overengineering
- React quirks
- Unprompted design changes
I often see that people online are annoyed by LLMs being lazy, and not giving them enough code directly. For me, it's the opposite. I always like to discuss a feature in pure english first, and only after that when we have everything decided, we move on to the actual code. If you read my conversations with Claude, you'll see that I often have to remind Claude of this, to not give me the code too quickly.
The thing here when you get the code too quickly, is that it also messes up the context, because now if you are not very explicit, Claude might think that what they just generated is the current state of some file, even though it's not. I don't think you ever want to just be sprayed with code by the LLMs, it's often indicative of a bad session when you get to that point.
First up, premature optimization. I live by the principle that I never add anything if I'm not sure why I just added. For example, if I add a new table to the schema, I won't create a bunch of indexes initially “just in case” they are needed in the future. I rather wait until I see proof that they are needed, and only them add them. This happened several times when developing this product, that when Claude gave me the CREATE TABLE statements, I also got a bunch of indexes “just in case”. Another similar example was when creating the prompt for generating flashcards. Instead of adding something small to the prompt and then testing if the results improve, Claude wanted to add 10 different things at the same time.
Another thing that is overengineering but not premature optimization, is when you just get an overly complicated solution for something that should simple. To avoid this, I literally found it very helpful to include in the prompt “this should be easy”, which seems to steer Claude into simple solutions.
Claude just loves useEffects for some reason. If I didn't explicitly tell Claude to not use them everywhere, this codebase would be a mess because of them. There where several times where Claude added a useEffect, and if just asked if it was really needed, they where like “No, not really” and removed it for a cleaner and simpler solution. Maybe the training data is just filled by useEffects everywhere?
Once in a while when you work on a feature, you'll get code back where code that is unrelated to the current feature is changed. For example, several times I got back code where the CSS was modified for something when we worked on something completely different.
Some smaller annoyances I have with the UI/UX is that sometimes Claude gives small parts of JSX in a large file, and I have to really look at the different tags and class names to see where I should insert the code. This might be a sign that I should split the JSX up into more components though. Also, unlike other people, I don't want the whole file every time for every change. For example, it seems like GPT-4o is tuned to always give the user back the whole file, and that can be annoying for small changes. I realize that this is a difficult UX problem for Anthropic and OpenAI since I'm having trouble even formulating when I want the whole file and when I don't.
Lack of higher-level thinking
- Taking a step back to think
- Holds very weak opinions
I feel like Claude rarely does this. One example is when we where thinking about how to render math notation correctly in the chat. All suggestions by Claude where that I should take the raw text given by the LLM, and do some crazy parsing to get it into Latex that we could render on the frontend with Katex. These examples made sense in a pre-LLM world, but now the better solution here is to just include in the system prompt what format the LLM should send us math in. Claude did not think of this. (To be fair, in the end our solution was a combination of parsing and prompt instructions, but the point still stands)
It's very easy to persuade Claude that something incorrect is correct. This can be annoying in discussions, when Claude becomes a yes-man that agrees with everything you say. I realize that the opposite would be worse though, if Claude held very strong opinions that were wrong.
Key takeaways
- Do not offload understanding of your system
- Have quick ways of getting relevant context to your clipboard
- Guide the LLM away from overengineering
- Think about your prompts, and think before you prompt
You will naturally have a worse understanding of your codebase when you don't write the code yourself by hand, but never let this go over board. Almost all my bad sessions with Claude can be attributed to this. Either read the code in detail every time you get it, or trust the code initially if it works and do code reviews later.
It's funny how many times I got a better AND simpler solution by just telling Claude “this should be simple” after giving them a task. I also found it beneficial to tell Claude to do everything step by step, and to never add something now if the reason is that "it might be needed in the future".
The less specific you are in prompts, the worse the result will be. For most of my bad sessions I was often unfocused and just wrote short prompts without really thinking about them. Also, it's often worth it to think about what the answer should be before asking the LLM so that you can quickly determine if what you got is good or bad.
Final thoughts
Developing Deepcards with Claude was definitely an interesting experience, and I hope this blog post showcases both the potential of current LLMs but also their limitations.
AI assisted development right now
I have to admit that I had to rely more on my technical expertise during this project than I initially anticipated. Initially we talked about non-technical people using LLMs to build products, and while I was skeptical initially, I'm even more skeptical of that now. This might sound disheartening if you are a non-technical person, but learning how to code is still very necessary if you want to build actual products.
I do think it's possible to build demoware as a non-technical person with Claude by just copy pasting what you get, but this won't lead to anything more than a demo. There would be so many strange bugs that you wouldn't know how to fix, and the codebase would be such a mess that if you were to hire engineers later they would have to redo everything from scratch anyways. If you are non-technical this might be difficult to grasp because you don't have the ability to differentiate good code and bad code. If we were to only develop Deepcards as demoware, the 30 conversations with Claude here could probably be cut down to 5 or something. It would still be possible to show the demo as I do here, but you wouldn't really be able to use the application. There is a huge difference between demoware and usable software. I honestly think that people not being able to see the difference between the two are a big reason for the divide between software engineers and VCs when talking about AI.
Bad stuff aside, I still think LLMs for coding are incredibly useful for certain parts of development, especially UI development as I explained earlier. If you are a developer that's building products that are similar in spirit to deepcards (as most web/mobile apps are), I think it's a big mistake if you don't use LLMs at all. If I were to only use LLMs for UI development, it would still be a significant improvement.
AI assisted development in the future
- Fundamental to LLMs
- Solvable by scaling
- Solvable by UI/UX improvements
If a problem is fundamental to LLMs, it means that to solve it we need a architectural breakthrough. Some people would argue that the “lack of higher-level thinking” issues go here, but honestly I'm not confident enough to have a strong opinion here. Yann LeCun would agree, but OpenAI and Anthropic probably wouldn't.
Means that this issue will be solved by LLMs by just training models with more data and/or compute. No architectural breakthroughs needed. I think some aspects of the code generation quirks can be placed in this bucket. I can imagine the overengineering and premature optimization issues will decrease with more training data.
Means that the problem doesn't have to be solved at the model layer, but can be solved at the product layer. Seems like most of my problems fall into this bucket, at least at a glance. It feels like the context and communications issues are with the UI/UX, but since no one has nailed it yet, I guess you could argue that there is a chance that this is still a model limitation. It's easy to claim that it's only a UI/UX issue, but until someone proves that, we can't know for sure.
How I look at this as a programmer
First of all, LLMs can obviously do stuff that you previously needed a programmer to do. This naturally leads to people thinking that programmers aren't needed anymore. BUT it's still a pipe dream that non-technical people can develop real software products, today. Models simply aren't good enough yet. This is also proven empirically, but you get the occasional demoware floating around on twitter which makes people think otherwise.
- Experienced people being annoyed because random people are telling them that LLMs can do what they do and spent their whole life learning
- Unexperienced people being annoyed or scared because random people are telling them that what they are learning is useless because an LLM can do it
- LLMs are overhyped by some people
- LLMs are incredibly useful
Okay, so LLMs can do some stuff that a programmer can do, but not everything? Yes.
Doesn't that mean we are going to need less programmers? Maybe, but what am I supposed to do about that? These things are notoriously hard to predict. I believe that if an AI model can do something as good as me, then it should do it and I should do something else.
Personally, I feel more powerful now as a programmer than I did before LLMs. This might seem contradictory to some of the things I've been saying, but I truly feel like my programming knowledge is more valuable now. I think this is because models are at this sweet spot where they are good enough to help programmers develop software, but they are not good enough to help non-programmers develop software.
This might change if we get models that are drastically better, but I don't think it will change if get models that are marginally better. So, to have an opinion on the future of programming, you all of a sudden need to be an expert in machine learning, because the future of programming kind of depends on how much better the models will get!
Personally, I will simply just continue focusing on what I think is fun, while embracing tools that make my life easier with open arms.